Explaining the Subtle but Critical Difference
High availability (HA) is a speciality and like most specialities, it has its own vocabulary and terminology. Our customers are typically very knowledgeable about IT but if they haven’t been working in an HA environment, some of our common HA terminology can cause a fair amount of confusion – for them and for us. They are simple-sounding but with very specific meaning in the context of HA. Three of these terms are discussed here – switchover, failover, and recovery.
What is a Switchover?
A switchover is a user-initiated action via the high availability (HA) clustering solution user interface or CLI. In a switchover, the user manually initiates the action to change the source or primary server for the protected application. In a typical switchover scenario, all running applications and dependencies are stopped in an orderly fashion, beginning with the parent application and concluding when all of the child/dependencies are stopped. Once the applications and their dependencies are stopped, they are then restarted in an orderly fashion on the newly designated primary or source server.
For example, if you have resources Alpha, Beta, and Gamma. Resource Alpha depends on resources Beta and Gamma. Resource Beta depends on resource Gamma. In a switchover event, resource Alpha is stopped first, followed by Beta, and then finally Gamma. Once all three are stopped, the switchover continues to bring the resources into an operational state on the intended server. The process starts with resource Gamma, followed by Beta, and then finally the start up operations complete for resource Alpha. 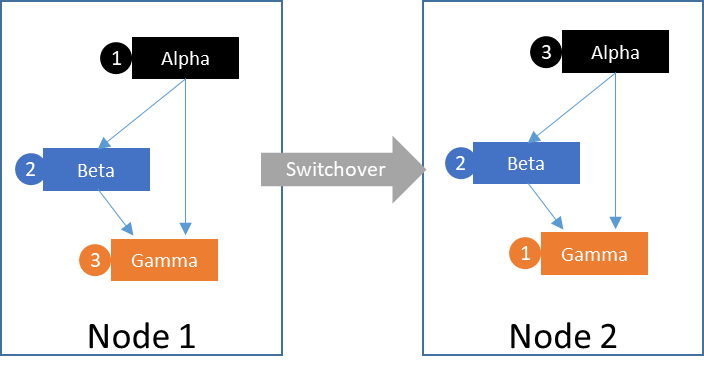
Traditionally, a switchover operation requires more time as resources must be stopped in a graceful and orderly manner. A switchover is often performed when there is a need to update software versions while maintaining uptime, performing maintenance work (via rolling upgrades) on the primary production node, or doing DR testing.
Key Takeaway: If there was no failure to cause the action, then it was a switchover
What is a Failover?
A failover operation is typically a non-user initiated action in response to a server crash or unexpected/unplanned reboot. Consider the scenario of an HA cluster with two nodes, Node A and Node B. In this scenario, all critical applications Alpha, Beta, and Gamma are started and operational on Node A. In this scenario, a failover is what takes place when Node A experiences an unexpected/unplanned reboot, power-off, halt, or panic. Once the HA software detects that Node A is no longer functioning and operationally available within the cluster (as defined by the solution), it will trigger a failover operation to restore access of the critical applications, resources, services and dependencies on the available cluster node, Node B in this case. In a failover scenario, because Node A has experienced a crash (or other simulated immediate failure) there are no processes to stop on Node A, and consequently once proper detection and fencing actions have been processed, Node B will immediately begin the process of restoring resources. As in the switchover case, the process starts with resource Gamma, followed by Beta, and then finally the start up operations complete for resource Alpha. Traditionally, a failover operation requires less time than a switchover. This is because the processing of a failover does not require any resources to be stopped (or quiesced) on the previous primary (in-service or active) node.
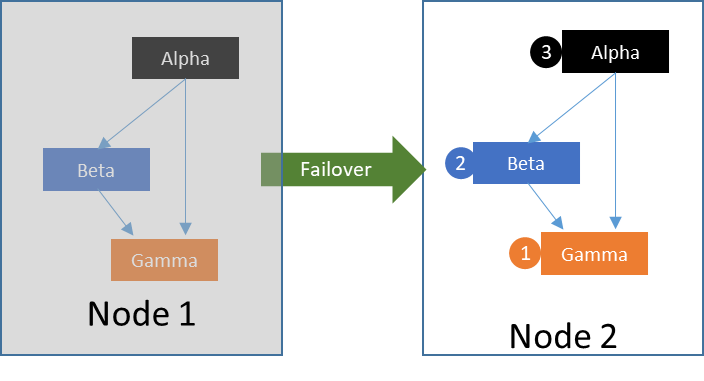
Key Takeaway: A failover occurs in response to a system failure.
What is Recovery?
A recovery event is easy to confuse with a failover. A recovery event occurs when a process, server, communication path, disk, or even cluster resource fails and the high availability software operates in response to the identified failure. Most HA software solutions are capable of multiple ways of handling a recovery event. The most prominent methods include:
- Graceful restart locally, then a graceful restart on the remote
- A restart is always attempted locally, if recovery is successful no further action occurs. If a local restart fails the next operation occurs
- If a local restart fails, resources are gracefully moved to the remote node
- Graceful restart locally, then a forced restart on the remote
- A restart is always attempted locally, if recovery is successful no further action occurs. If a local restart fails the next operation occurs.
- Resources are moved to the remote node by fencing the primary node
- Forced restart on the remote
- A restart is never attempted locally
- Resources are always forced to the next available cluster node as described in method 2b.
- Forced server restart, no remote failover
- A restart is always attempted locally
- If a local restart fails, the primary node is restarted to attempt to recover services.
- Resources will not fail to a remote system
- Policy based local restart, then remote
- Policies may govern the number of retries before a remote attempt a recovery occurs
Due to the number of variations in recovery policy it is easy to see a recovery event that resembles the behavior of a switchover. This is often the case in methods 1 and 5. In these scenarios applications and services are gracefully stopped in an orderly fashion before being started on the remote node. Methods 2 and 3, customers will often see a behavior similar to a failover. In methods 2 and 3, the primary server is restarted or fenced by the HA software which creates an observable behavior similar to a failover. Method 4 is typically an option that is rarely used, but is a hybrid of both a switchover and a failover. Method 4 begins with a graceful stop of the applications and services, followed by a restart of the applications and services (much like a switchover). However, if the local restart of the applications and services fails, the system will be restarted (much like a failover), but without actually failing to the remote cluster node. While rare, Method 4 is often invoked in cases where an unbalanced cluster is present, or used with a policy based methodology.
Key Takeaway: A recovery event depends on the method chosen
HA terminology between vendors is an area where common terms can take on different meanings. As you deploy and maintain your cluster solution with enterprise applications, be sure that you understand the solution provider terms for failover, switchover and recovery. And, while you are at it, make sure you know whether the restaurant will put the sauce on the side (in a saucer), or on the side (your mashed potatoes).
-Cassius Rhue, VP, Customer Experience
Have questions about high availability or need guidance navigating HA terminology like switchover, failover, or recovery? Reach out to our experts at SIOS for personalized support and insights.


