White Paper: Automated Multitarget Disaster Recovery for SAP HANA
Thank you for registering
The Complexity of High Availability and Disaster Recovery | Pressure to Ensure Availability | Cloud Computing High Availability | High Availability Challenge for IT Teams | Complex, Manual Failover and Replication | SIOS Automated Multitarget for SAP HANA | Fast, Efficient Disaster Recovery Testing | Near-Zero Downtime Maintenance | Failover Avoidance for Rapid Recovery | Cloud Disaster Recovery Sites | Optimize HANA Performance |
The Industry’s Most Comprehensive Protection
ENTERPRISE RESOURCE PLANNING (ERP) systems like SAP are some of an organization’s most critical systems. They integrate core business functions, sales, inventory, finance, and payroll. They comprise several interdependent software modules, including the SAP application, support services such as ASCS ERS, and the SAP HANA database. The criticality of these systems compel IT administrators to implement reliable high availability (99.99% uptime) and disaster recovery strategies.
The Complexity of High Availability and Disaster Recovery
Applications run at the top of the so-called IT stack, making them intrinsically complicated to protect. For applications to be available, every component in the stack also needs to be operational, compatible, and available, including the network, storage, server hardware, operating system, application, and related software.
To provide high availability (HA), companies run these applications and/or modules on a primary server and use HA clustering solutions to detect failures and orchestrate the failover of application operation to a secondary server. At the same time, data stored on the primary server is replicated to a secondary server so, in the event of a failure, the operation can continue with a recovery point of zero. When a third or fourth node is added for disaster recovery (DR), replication must be managed and integrated to ensure all data stays in sync and protected before, during, and after failover.
While HA failover can be accomplished with complex clustering solutions such as those provided by open-source OS vendors, these solutions require a great deal of manual scripting to ensure the various dependencies and application-specific requirements are accommodated, and that operation can continue according to SAP best practices post failover. In this paper, you’ll learn about the challenges around implementing HA for SAP HANA and solutions to make your life easier as an administrator. Your clustering software should be simple, automatic, and failover reliably while maintaining SAP best practices.
Pressure to Ensure Availability
IT organizations are constantly under pressure to deliver HA, despite challenging budgets, staffing shortages, and limited resources. But downtime is a fact (computer systems will inevitably fail), and the
costs of downtime go beyond the costs associated with the outage. Downtime dramatically increases the stress level in already overworked IT organizations. During a system failure, admins typically go into crisis mode, meaning they must drop all their current tasks to bring systems back online. After the outage, busy admins must dedicate more time to performing a root cause analysis of the failure. These stressors lead to errors from admins because failover processes often depend on sequential, manual steps with complex decision trees.
While cloud computing purports to improve availability compared to traditional on-premises systems, it also adds layers of complexity to an already complicated technology stack. Cloud HA service-level agreements (SLAs) cover hardware but the end user is responsible for providing protection against the many software-related sources of downtime. In addition, many organizations are challenged with finding staff with a deep understanding of cloud computing. ERP systems, such as SAP HANA, are overly complex on their own, and adding the complexity of cloud infrastructure—with significant differences in networking and storage—is even more challenging.
While the public cloud may improve the availability of an individual virtual machine (VM), cloud vendors still have outages, even in the form of regional service failures. To protect systems running on cloud platforms, administrators also need to ensure that architectures are designed to protect against those regional failures. Moving beyond cloud-related outages, systems availability is still affected by outage vectors like patching and various operational failures.
Cloud Computing High Availability
It does help to understand the basic availability constructs of cloud computing platforms. Like an on-premises environment, in the cloud, application HA and DR are based on the concept of redundancy (HA)
and geographic separation (DR). In other words, running an application on a primary node and, in the case of a failure, moving the operation to a redundant secondary node for HA. Keeping the secondary or
additional nodes geographically separated provides protection in case of a sitewide disaster.
While this terminology may vary across vendors, the general constructs are common. The highest-level concept is a cloud region consisting of several physical data centers, all of which exist within a network latency boundary. The basic availability construct is working to eliminate single points of failure. This strategy would be implemented in a traditional on-premises data center by ensuring that two VMs never run in the same virtualization cluster or that traditional servers are geographically separated. Another key concept for cloud workloads is availability zones which are data centers with different networking and power sources. They typically have a low enough latency target to support synchronous replication to protect against data loss.
High Availability Challenge for IT Teams
In most organizations, highly skilled, often very specialized IT architecture teams design the ERP system and its components and turn it over to a system administration team responsible for its day-to-day operation. When a failure happens, the architects are usually unavailable to troubleshoot the problem. Since HA touches every part of the IT stack, to troubleshoot downtime, companies might have to assemble a team of IT specialists from networking, storage, database, and application groups to bring the system back online.
Complex, Manual Failover and Replication
For more than 20 years, most SAP and HANA environments have operated in open-source Linux environments such as SUSE Linux and Red Hat Enterprise Linux. Although this broad adoption has allowed for a great deal of automation and consistent troubleshooting, HA clustering for stateful Linux-based workloads has several weaknesses. The most popular Linux OS brands, including Red Hat Pacemaker and SUSE Linux HAE, require complicated scripting to handle failover dependencies, state management, and replication. These functions are complex in a standard two-node cluster. Adding third or fourth nodes in different data centers or cloud availability zones for DR purposes can increase the complexity of both failover and replication exponentially.
For example, if Pacemaker clustering isn’t configured in a specific way, it may cause an unnecessary failover after an automated failover when it tries to fail back to the original primary node. To avoid these situations requires a thorough knowledge of your clustering environment and detailed, manual scripting and management of domain name services (DNS) and certificates. In a HANA HA/DR environment, replication is performed by HANA System Replication (HSR), which must be managed by the clustering software. In the event of a failover from a primary node to a secondary node, the secondary node must start replicating to the DR location. In an HAE or Pacemaker environment, that replication change has to be scripted manually while in crisis mode—responding to a failover. When the issue that caused the failover is remediated, you have to manually script the restoration of normal operation.
SIOS Automated Multitarget for SAP HANA
SIOS LifeKeeper for Linux is designed to simplify the complexity of HA/DR in the SAP HANA environment through advanced automation of both the failover and HSR management processes. SIOS LifeKeeper comes with modules called application recovery kits (ARKs) that provide application-specific automation and intelligence. The HANA ARK enables automated multitarget clustering for the most comprehensive HA/DR solution in the industry.
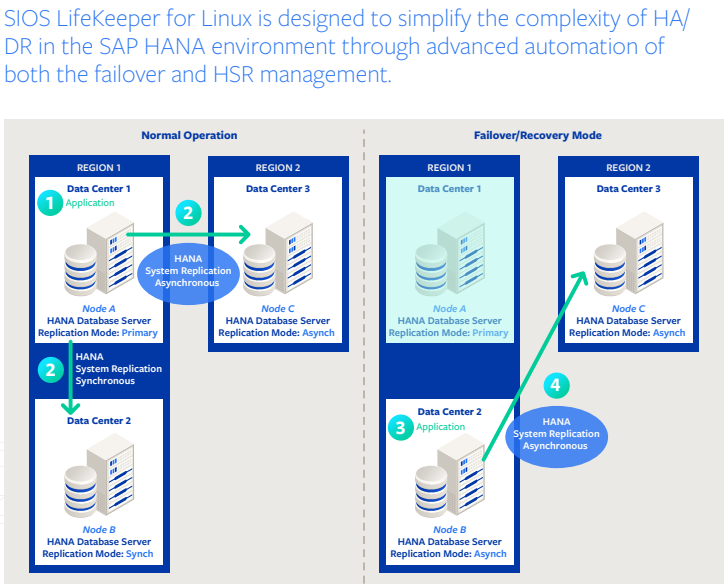
As shown in Figure 1, in normal operating conditions, HANA (1) is running on primary node A located in Data Center 1, Region 1. HSR replicates the HANA database from Node A to secondary Nodes B and C (2). If SIOS LifeKeeper detects an application availability issue on Node A, it automatically orchestrates an application failover to Node B (3) and switches DR replication from Node B to Node C (4). When normal
operation is restored to Node A, SIOS LifeKeeper automatically restores the original replication settings with a single click.
SIOS LifeKeeper has a straightforward installation process, performed in minutes, not hours, and doesn’t require complex scripting solutions. SIOS LifeKeeper combines this knowledge and simplicity with deep hooks into the SAP HANA services to ensure a reliable failover with the SAP handshake feature.
Fast, Efficient Disaster Recovery Testing
Disasters take many forms, and the only way to ensure your HANA database is protected is to perform regular testing. However, many IT teams are hesitant to perform regular maintenance and rigorous DR
testing due to their concerns about downtime and complexity in Linux HA/DR environments.
Near-Zero Downtime Maintenance
SIOS LifeKeeper leverages SAP HANA takeover with handshake feature to speed switchover and switchback and enable near-zero downtime maintenance by rapidly preloading data in the HANA in-memory database.
Failover Avoidance for Rapid Recovery
When SIOS LifeKeeper detects a failure on the primary cluster node, it has the ability to take one of two recovery steps to bring the systems back on line. If the database on the standby node is in synch with the database on the primary node and data is loaded in memory, LifeKeeper will perform an immediate failover to the standby node. However, if the administrator prefers, LifeKeeper can also attempt to restart the application to bring operations back online on the primary node without a failover. If the restart does not succeed, it then executes a complete failover to the standby server. LifeKeeper also alerts an administrator that the failover has happened.
Cloud Disaster Recovery Sites
SIOS LifeKeeper HANA multitarget works both on-premises or in the cloud. Add a DR node in the cloud to your on-premises HANA cluster configuration for disaster protection without the cost of maintaining an on-premises DR site.
Optimize HANA Performance
Businesses have increased demand for system uptime, while IT organizations are seeing their budgets and headcounts cut. These trends can challenge the best system administrators for essential business systems like SAP HANA. SIOS LifeKeeper simplifies the deployment and operation of highly available Linux clusters for SAP HANA and allows you to support failures without data loss, monitor your environment, and build protections against regional and data center failure, either in your cloud or your data center.
To learn more about SIOS SAP-Certified High Availability for SAP and HANA in Physical, Virtual or Cloud Environments, please visit https://us.sios.com/solutions/sap-high-availability/.