
Downtime has become more costly than ever before for modern businesses. The ITIC 2021 Hourly Cost of Downtime Survey found that in 91% of organizations, one hour of downtime in a business-critical system, database, or application costs an average of more than $300,000, and for 18% of large enterprises, the cost of an hour of downtime exceeds $5 million.
High availability (HA) is an attribute of a system, database, or application that’s designed to operate continuously and reliably for extended periods. The goal of HA is to reduce or eliminate unplanned downtime for critical applications, which is achieved by eliminating single points of failure by incorporating redundant components and other technologies in the design of a business-critical system, database, or application.
SLAs and HA Metrics
Service-level agreements (SLAs) are used by service providers to guarantee that a customer’s business-critical systems, databases, or applications are up and running when the business needs them.
IDC has created an SLA model that defines uptime requirements at five levels as follows:
- AL4 (Continuous Availability – System Fault Tolerance): No more than 5 minutes and 15 seconds of planned and unplanned downtime per year (99.999% or “five-nines” availability)
- AL3 (High Availability – Traditional Clustering): No more than 52 minutes and 35 seconds of planned and unplanned downtime per year (99.99% or “four-nines” availability)
- AL2 (Recovery – Data Replication and Backup): No more than 8 hours, 45 minutes, and 56 seconds of planned and unplanned downtime per year (99.9% or “three-nines” availability)
- AL1 (Reliability – Hot Swappable Components): No more than 87 hours, 39 minutes, and 29 seconds of planned and unplanned downtime per year (99% or “two-nines” availability)
- AL0 (Unprotected Servers): No availability or uptime guarantee
According to ITIC, 89% of surveyed organizations now require “four-nines” availability for their business-critical systems, databases, and applications, and 35% of those organizations further endeavor to achieve “five-nines” availability.
In addition to uptime and availability, two other important HA metrics are Recovery Time Objectives (RTOs) and Recovery Point Objectives (RPOs). RTO is the maximum tolerable duration of any outage and RPO is the maximum amount of data loss that can be tolerated when a failure happens. Unlike RTO and RPO metrics for disaster recovery which are typically defined in hours and days, RTO and RPO metrics for business-critical systems, databases, and applications are often only a few seconds (RTO) and zero (RPO).
HA Clustering
HA clustering typically consists of server nodes, storage, and clustering software.
Traditional Clustering
A traditional, on-premises HA cluster is a group of two or more server nodes connected to shared storage (typically, a storage area network, or SAN) that are configured with the same operating system, databases, and applications (see Figure 1).
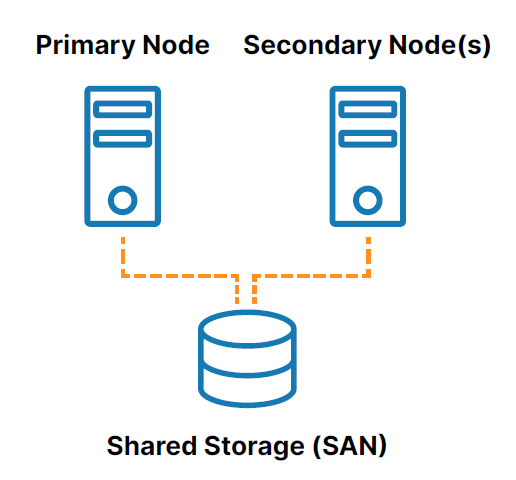
One of the nodes is designated as the primary (or active) node and the other(s) are designated as secondary (or standby) nodes. If the primary node fails, clustering allows a system, database, or application to automatically fail over to one or more secondary nodes and continue operating with minimal disruption. Since the secondary node is connected to the same storage, operation continues with zero data loss.
However, the use of shared storage in the traditional clustering model creates several challenges, including:
- The shared storage itself is a single point of failure that can potentially take all of the connected nodes in the cluster offline.
- SAN storage can also be costly and complex to own and manage.
- Shared storage in the cloud can add significant, unnecessary cost and complexity and some cloud providers don’t even offer a shared storage option.
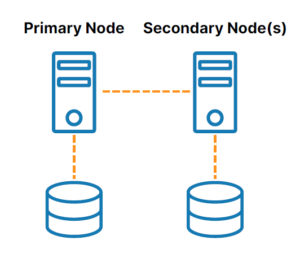
SANless Clustering
SANless or “shared nothing” clusters (see Figure 2) address the challenges associated with shared storage. In these configurations, every cluster node has its own local storage. Efficient host-based, block-level replication is used to synchronize storage on the cluster nodes, keeping them identical. In the event of a failover, secondary nodes access an identical copy of the storage used by the primary node.
Clustering Software
Clustering software lets you configure your servers as a cluster so that multiple servers can work together to provide HA and prevent data loss. A variety of clustering software solutions are available for Windows, Linux distributions, and various virtual machine hypervisors. However, each of these solutions limits your flexibility and deployment options and introduces various challenges such as technical complexity and expensive licensing.
Don’t Wait for Disaster to Strike
HA is crucial for business-critical systems, databases, and applications. But with the myriad platforms available, complexity ramps up significantly. That’s why an application-aware solution makes so much sense. What you need is a trusted partner who has extensive expertise in high availability—a partner like SIOS, which has the technological know-how to ensure that your business stays up and running.
Don’t wait for an outage or disaster to find out if you have the resiliency your business needs. Schedule a personalized demo today at https://us.sios.com to see what SIOS can do for your business.


